多机多卡的实现
图中在迭代每一轮时,不同设备首先统一读取当前参数的取值,并随机获取一小部分数据
然后在不同设备上运行反向传播过程得到在各自训练数据上的参数的梯度
注意:虽然所有设备使用的参数是一致的,但是因为训练数据不同,所以得到的参数的梯度可能不一样
当所有设备完成反向传播的计算之后,需要计算出不同设备上参数梯度的平均值
最后再根据平均值对参数进行更新
Batch Norm的实现
- 目的
Batch Norm 对输入数据进行归一化,使得每一层的数据分布尽量保持相同
- 操作
在通道维度上进行归一化,例如多张RGB特征图(N,C,H,W),先求R通道上所有batch的均值、方差,进行归一化,得到均值为0方差为1的正态分布的数据后再进行拉伸
所以Batch Norm需要学习的参数有2*C个
- 参数
Batch Norm 两个需要训练的参数:scale / shift
$$
y = scale * x + shift
$$
对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale * x + shift),每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,意思是通过scale和shift把这个值从标准正态分布左移或者由移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。
还有两个参数,使用动量更新的方式记录全局的均值和方差,为了在测试集上使用,这两个参数不参与训练
- BN的优点
- 减小了梯度弥散,提升了训练速度,收敛过程大大加快,还能增加分类效果。
- Batchnorm本身上也是一种正则的方式(主要缓解了梯度消失),可以代替其他正则方式如dropout等。
- 调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等。
- BN的缺陷
batch normalization依赖于batch的大小,当batch值很小时,计算的均值和方差不稳定。
激活函数
Softmax
$$
Softmax = \frac{e^{i}}{\sum_{j}{e_{j}}}
$$
导数:
$$
S’ = -S_{j}S_{i}, i\neq j
$$
$$
S’ = (1-S_{i})S_{i}, i= j
$$
卷积
卷积输入是(n, c_in, w, h),输出是(m, c_out, w, h),kernel=k, s=1写一下这个卷积的计算量。
卷积核参数 k* k* c_in *c_out
k* k* c_in *c_out *((w-k+pad)/s + 1) * ((h-k+pad)/s + 1)
问:有没有什么减少计算量的方法?
答:只记得ResNet提出的时候说是卷积核为1能减少计算量。
问:那它是怎么减少的呢?
答:计算量k×k变成1×1了,当然减少了计算量。
问:那对后面计算量的影响呢?
答:把后一层的c_in变小了。
问:一个3×3的卷积核经过两层后,它的感受野是多少?
答:5。
经过一层是3。逆向思考,从11往外卷一层是33再往外卷一层是55,在往外是77
损失函数
问:L1损失函数和L2损失函数有什么区别?
答:L1是绝对值之和,L2是平方和求平方根。L1是稀疏的,在梯度更新时,不管 L1 的大小是多少(只要不是0)梯度都是1或者-1,所以每次更新时,它都是稳步向0前进。
并且因为是绝对值,所以对异常值不敏感,L2计算方便
Smooth L1:
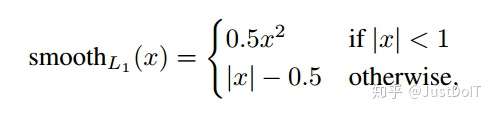
smooth L1损失函数曲线如下图所示,作者这样设置的目的是想让loss对于离群点更加鲁棒,相比于L2损失函数,其对离群点(指的是距离中心较远的点)、异常值(outlier)不敏感,可控制梯度的量级使训练时不容易跑飞。
训练崩溃
- 学习率过大,网络震荡导致的。调小学习率
- 损失函数遇到边界值,可能会除0。在可能遇到0的计算上加上一个极小数,比如1e-8
- 原始数据太过于稀疏,对原始数据进行归一化,标准正太,0/1归一化
Dataloader
40、对多线程了解吗
了解,但没写过
41、那如果让你自己实现pytorch里面的dataloader,你怎么可以使它加载快点
用多线程,
pin_memory 加载到锁业内存上
过拟合
训练数据集样本单一,样本不足。如果训练样本只有负样本,然后那生成的模型去预测正样本,这肯定预测不准。所以训练样本要尽可能的全面,覆盖所有的数据类型。
训练数据中噪声干扰过大。噪声指训练数据中的干扰数据。过多的干扰会导致记录了很多噪声特征,忽略了真实输入和输出之间的关系。
模型过于复杂。模型太复杂,已经能够“死记硬背”记下了训练数据的信息,但是遇到没有见过的数据的时候不能够变通,泛化能力太差。我们希望模型对不同的模型都有稳定的输出。模型太复杂是过拟合的重要因素。
防止过拟合:
数据增强
正则化
Early stop 早停
Drop Out
在训练过程中会产生不同的训练模型,不同的训练模型也会产生不同的的计算结果。随着训练的不断进行,计算结果会在一个范围内波动,但是均值却不会有很大变化,因此可以把最终的训练结果看作是不同模型的平均输出。
它消除或者减弱了神经元节点间的联合,降低了网络对单个神经元的依赖,从而增强了泛化能力。
正则化
L1正则化(LASSO)可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化(岭回归:Ridge)产生平滑解,获得值很小的参数,可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
完全二叉树
leetcode958 判断是否是完全二叉树:
完全二叉树:
首先对满二叉树按照广度优先遍历(从左到右)的顺序进行编号。
一颗深度为k二叉树,有n个节点,然后,也对这棵树进行编号,如果所有的编号都和满二叉树对应,那么这棵树是完全二叉树。
GAN的训练方式
https://blog.csdn.net/qq_38335768/article/details/120883094
第一步:向鉴别器展示一个真实的数据样本,告诉它该样本的分类应该是1.0。
——————然后用损失来更新鉴别器。
第二步:向鉴别器展示一个生成器的输出,告诉它该样本的分类应该是0.0。
——————我们只用损失来更新鉴别器。注意,不要更新生成器!!!!
——————我们不希望它因为被鉴别器识破而收到奖励。
第三步:向鉴别器显示一个生成器的输出,告诉生成器结果应该是1.0。
——————我们只用结果的损失来更新生成器,而不更新鉴别器。
——————因为我们不希望因为错误分类而奖励生成器。
这就是大多数GAN训练方案的核心。