再探 ViT (更深更慢更强)
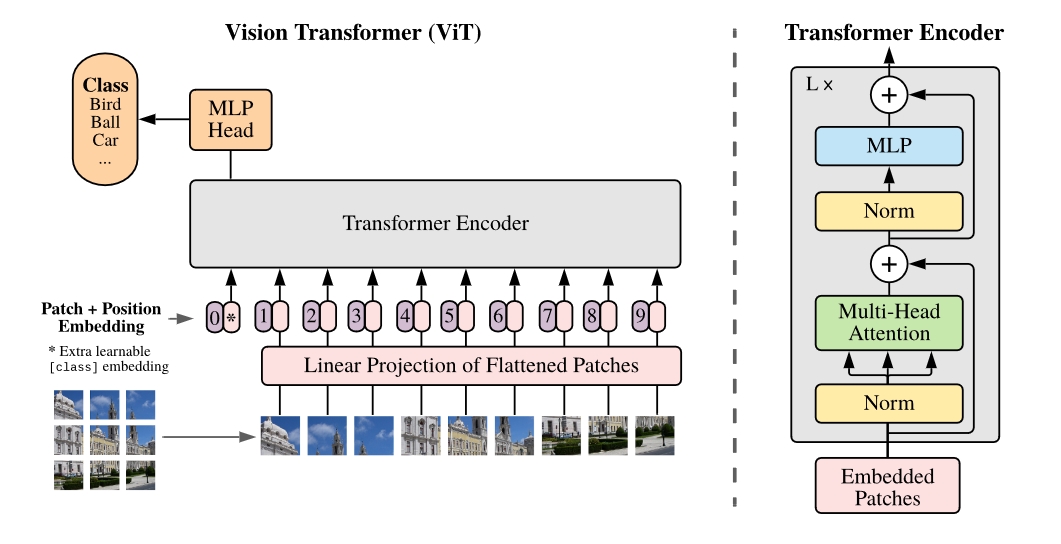
ViT主要结构:
Linear Projection (Patch + Position Embedding)
Transformer Encoder
MLP head
Embedding
Transformer输入的是一小块一小块的Patch,所以在这一步需要把图片切片,将这一小块的图像视为token,在Transformer中计算每个token的相关性
CNN:通过卷积+池化的方式下采样,加深模型深度。但是CNN对边缘像素的响应很弱,(越靠近边缘的地方被卷积次数少,贡献更少);由于滑窗特性,CNN只能计算临近像素的相关性,某些空间信息没有办法很好的利用
token要以向量形式被Transformer接收,所以在这一步把shape: [H,W,C]的patch,通过Embedding转换为shape:[num_token, embed_dim]的token
输入图像 $224\times 224 \times 3$,Patch大小为 $16\times 16 \times 3$
图片拆分为 $(224/16)^{2}=14^{2}=196$个Patch
映射到向量中就是embed_dim就是 $16\times16\times3=768$维
token的shape就是 [196, 768]
代码中,patch剪裁是通过Patch_size大小的卷积核和同样Patch_size的步长实现的,通道Channel = 768 = Embed_dim,H/W=14分别是切片的Patch大小
(所以这个里面,Conv是可训练的而不是固定权重的,不过其实问题不大,对所有Patch的权重都一样)
1 2 3 4 5 6 7## Initialization self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) # x [B, 3, 224, 224] -> self.proj(x) [B, 768, 14, 14] # flatten: [B, C, H, W] -> [B, C, HW] # transpose: [B, C, HW] -> [B, HW, C] x = self.proj(x).flatten(2).transpose(1, 2)Class Embedding
感觉很多这部分都讲的不是很明白 … (推锅.jpg)
Cls Token 感觉是借鉴了Attention方案,实现Avg Pool的一个方式
比如在流程图中,一张图片切分成了9份Patch,9个向量在提取特征之后聚合的时候,CNN的方式是使用池化,但是这里使用一个可训练的参数作为Key来选择9个向量中哪个Value价值更大一些,而且因为是可训练的参数参与到所有的Token里面,所以表示的是一个全局的信息
而作为Key要和原本的Token的大小一致,shape: [1, 1, embed_dim]
而且cls_token的位置固定,始终排在第一个
1 2 3 4 5 6 7 8 9# Initilization # embed_dim = 768 self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) ## [B, 1, embed_dim] cls_token = self.cls_token.expand(x.shape[0], -1, -1) # x [B, num_token, embed_dim] -> [B, 1 + num_token, embed_dim] x = torch.cat((cls_token, x), dim=1)Position Embedding
感觉很多这部分都讲的不是很明白 … (推锅.jpg)
https://zhuanlan.zhihu.com/p/631363482/ 中解释了,因为Transformer使用了自注意机制,会使得序列前后两个元素无视其位置,但是在nlp中这是与语言相违背的(我爱你vs你爱我),所以需要加位置编码加以区分
但是!!! nlp里纯正的Tranformer使用位置编码,绝对、相对、正余弦编码。但是在ViT的中的位置编码设置成了可学习的参数,这个比较费解了
https://zhuanlan.zhihu.com/p/658262098?utm_psn=1704466199985999872
Nips 23的一篇文章:“在 MoCo v3 的论文中有一个很有趣的现象:ViT 带与不带 position embedding,在 ImageNet 上的分类精度相差无几。”
所以说这个位置编码应该如何发挥最大的作用???
1 2 3 4## Init self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim)) x = self.pos_drop(x + self.pos_embed)
Code
| |
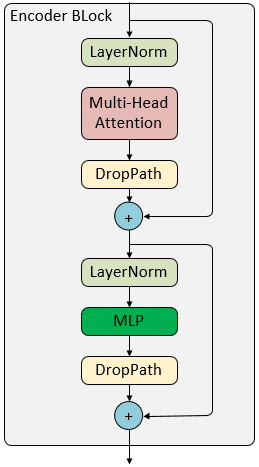
Transformer Block
Layer Normalization
Batch Norm 是针对所有的样本计算均值和方差,LN是针对某一个样本
BN适用于不同mini batch数据分布差异不大的情况,而且BN需要开辟变量存每个节点的均值和方差,空间消耗略大;而且 BN适用于有mini-batch的场景。LN只需要一个样本就可以做归一化,可以避免 BN 中受 mini-batch 数据分布影响的问题,也不需要开辟空间存每个节点的均值和方差。
Multi-Head Attention
Transformer潘多拉的磨合,ALL Y0U NEED罪孽的开端
$$Att(Q,K,V) = Softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V$$
技术上:
- 首先把token向量经过线性层映射成三个不同的向量 Query (Q), Key (k), Value (V) - 通过$Softmax(\frac{QK^{T}}{\sqrt{d_{k}}})$来获得各个token的注意力,即点积,余弦相似度 - 将这个注意力,也就是权重赋予到各个token向量中1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25class Attention(nn.Module): def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0.1, proj_drop=0.): super().__init__() self.num_heads = num_heads head_dim = dim // num_heads self.scale = head_dim ** -0.5 self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop) self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop) def forward(self, x): B, N, C = x.shape qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple) attn = (q @ k.transpose(-2, -1)) * self.scale attn = attn.softmax(dim=-1) attn = self.attn_drop(attn) x = (attn @ v).transpose(1, 2).reshape(B, N, C) x = self.proj(x) x = self.proj_drop(x) return x技术细节都挺容易,重要的是怎么理解Query, Key 和 Value这三个东西的含义
有点只可意会,不可言传的意味…
通过线性层映射,就当他是 Query, Key 和 Value,这个不要去理解(去感受,hhh,诺兰上身),就当他是
Value指的是这个Token最根本的含义,举个不恰当的例子,比如“Think”,“Thought”,他们的 Value 应该都是一样的,都是“想”的意思
Key指的是这一个Token的关键词,也就是最能代表这个Token的向量,相当于一个索引,和Query是相关联的
Query指的根据这个Token的含义想要找出下一个最相关的Token的查询键,相当于我这个Token我已经知道他的含义Value,并且在字典中定义了查找到这个Token的关键词Key,那么我要查找和我这个Token和其他Token之间的关系,就要通过Query去找Key,通过Query建立起来,一句话、一幅图中每个Token之间的联系
其他的一些理解可以参考 https://zhuanlan.zhihu.com/p/410776234
ChatGPT的解释
Q (query):表示“我要找什么”
K (key):表示“每个 token 拥有什么特征”
V (value):表示“每个 token 提供的信息”
Softmax(QK^T):算出来的是 [N, N] 的相关性矩阵,表示每个位置的 query 对所有位置的 key 的注意力分布。
👉 换句话说:query 不仅能看到自己,还能选择性地聚合所有 token 的信息。
另一个是多头的概念,这个真的很有用,但是真的很诡异,我觉得多头有用的地方是因为维度太大了,导致Softmax的时候很多是0导致溢出,所以把维度分摊了出去,再回收,可以保证进行有效计算
举个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22## 2头的注意力 model = Attention(dim=8, num_heads=2) ## 1个Batch里面有3个Token,每个Token有8个维度 def forward(self, x = torch.rand([1, 3, 8])): B, N, C = x.shape qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) ## 通过多头(num_heads=2),将8个维度拆分成了[2, 4] ## q [1, 2, 3, 4] ## k [1, 2, 3, 4] ## v [1, 2, 3, 4] q, k, v = qkv[0], qkv[1], qkv[2] attn = (q @ k.transpose(-2, -1)) * self.scale attn = attn.softmax(dim=-1) attn = self.attn_drop(attn) ## attn [1, 2, 3, 3] 得到的注意力 x = (attn @ v).transpose(1, 2).reshape(B, N, C) x = self.proj(x) x = self.proj_drop(x) return x其他啥Multi-heads的解释感觉都有点玄幻
DropPath
其实和dropout的作用一样,将深度学习模型中的多分支结构随机删除,防止过拟合
一般加在运算层(线性运算,注意力运算,卷积运算)的后面
MLP
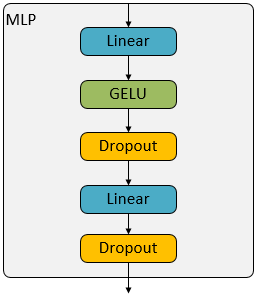
MLP is all you need …
全连接层加上激活函数和DropOut
Code
| |
MLP Heads
分类头,MLP少了一层后面的,和CNN的套路没啥区别
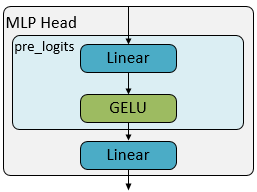
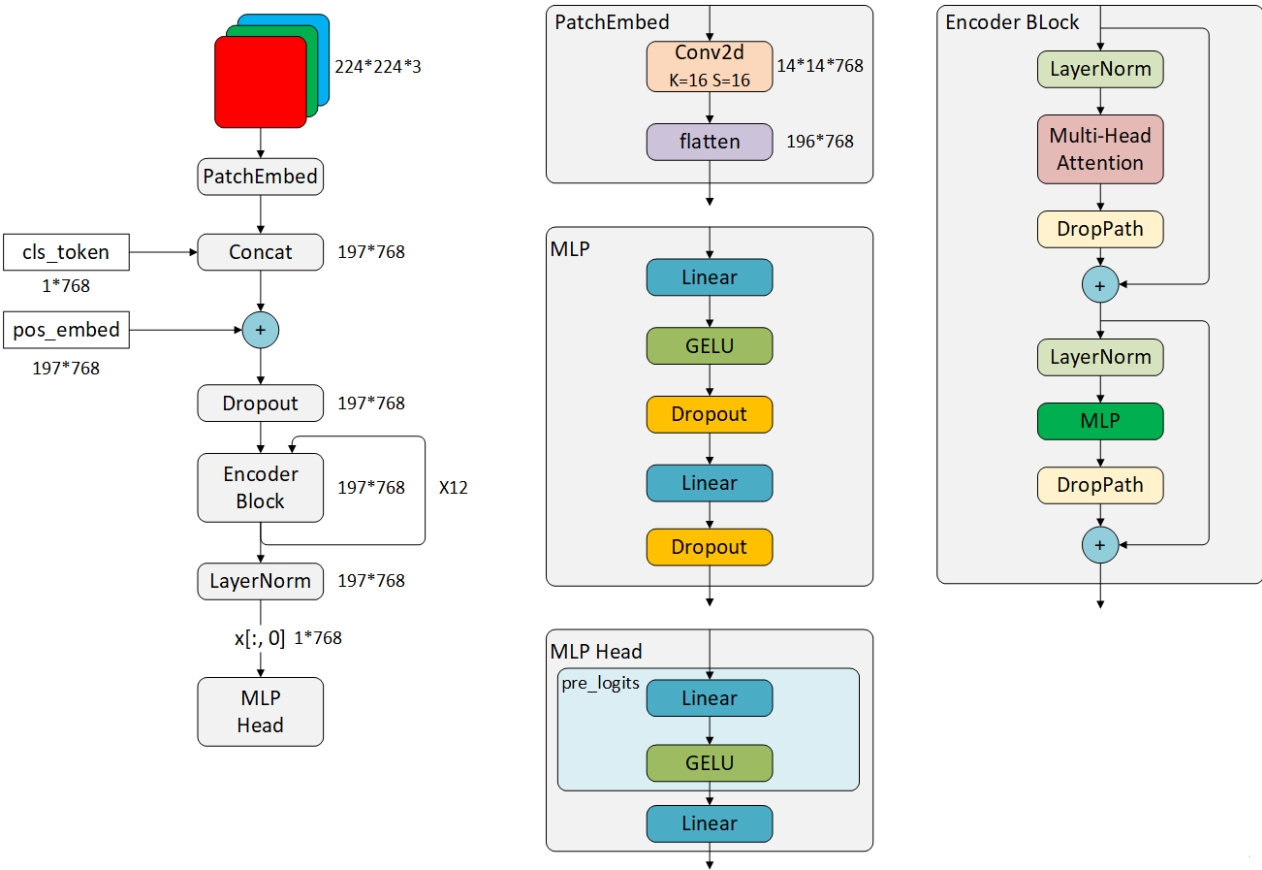
总览
具体来说,ViT-B/16整体网络结构如下图