Mask Autoencoder
MAE想法很简单,很有效,很牛逼,这里主要讨论一些实现细节,以官方代码为准
ViT (models_mae.py)
MAE的ViT和原版ViT还是有点区别,这里主要讲区别:
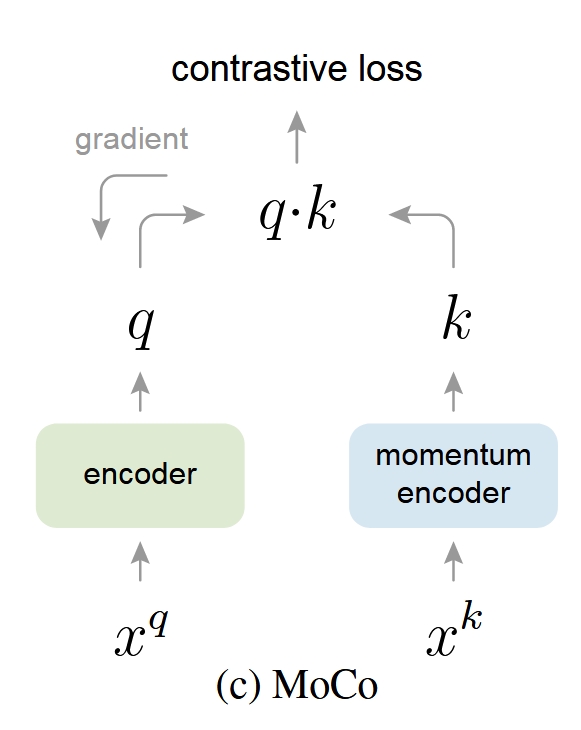
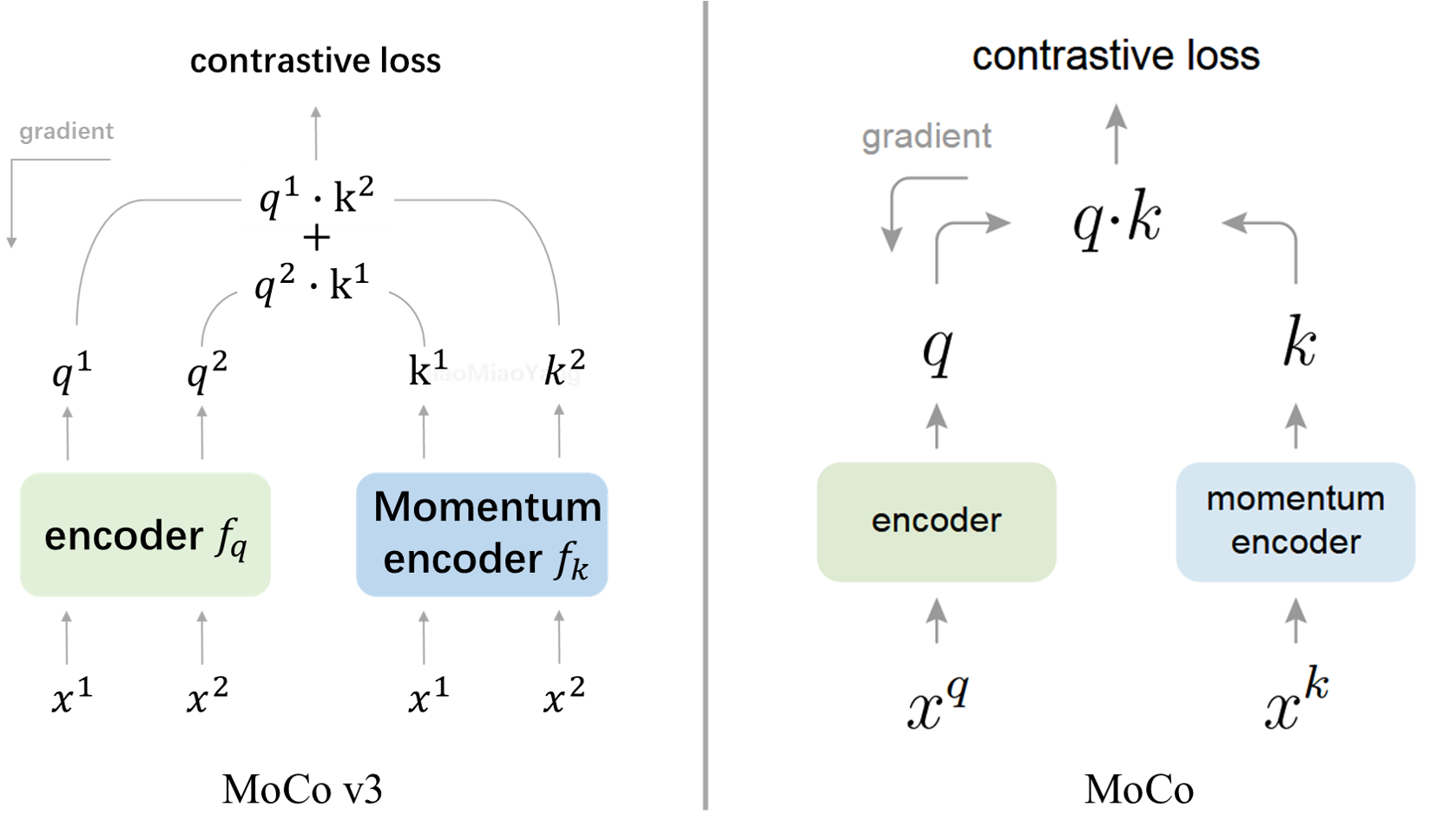
MoCo v.s. MoCo v3
MoCo v3 摘要第一句话太有欺骗性了,hhh
This paper does not describe a novel method. Instead, it studies a straightforward, incremental, yet must-know baseline given the recent progress in computer vision: selfsupervised learning for Vision Transformers (ViT).
结果我就天真以为和MoCo差不多,这就是大佬的自谦嘛,创新点暴打一我等众水文
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| # f_q, f_k: encoder networks for query and key
# queue: dictionary as a queue of K keys (CxK)
# m: momentum
# t: temperature
f_k.params = f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries: NxC
k = f_k.forward(x_k) # keys: NxC
k = k.detach() # no gradient to keys
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward()
update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatch
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| # MoCo v3
# f_q: encoder: backbone + proj mlp + pred mlp
# f_k: momentum encoder: backbone + proj mlp
# m: momentum coefficient
# tau: temperature
for x in loader: # load a minibatch x with N samples
x1, x2 = aug(x), aug(x) # augmentation
q1, q2 = f_q(x1), f_q(x2) # queries: [N, C] each
k1, k2 = f_k(x1), f_k(x2) # keys: [N, C] each
loss = ctr(q1, k2) + ctr(q2, k1) # symmetrized
loss.backward()
update(f_q) # optimizer update: f_q
f_k = m*f_k + (1-m)*f_q # momentum update: f_k
# contrastive loss
def ctr(q, k):
logits = mm(q, k.t()) # [N, N] pairs
labels = range(N) # positives are in diagonal
loss = CrossEntropyLoss(logits/tau, labels)
return 2 * tau * loss
|
ALBEF
多模态版本的MoCo, hhh。大佬之间真的太卷了,还是使用queue来维护了整个key字典